As usual, I’m self-documenting a project while I work on it. Rustdesk is an open source remote control utility that caught my eye about a year ago; it’s cross platform and allows you to self-host your own “relay server” so that you can connect securely from one machine on a private network to a machine on a different private network without needing to faff about with port forwarding or similar nonsense.
Most of the docs seem focused around running it as a Docker instance, which I didn’t particularly want to do. They also weren’t clear AT ALL about where important files live, how they’re run, etc.
First up: you’ll need to install THREE separate .deb files. Go to the rustdesk-server releases page here and download the rustdesk-server-hbbr, rustdesk-server-hbbs, and rustdeskserver-utils packages for your architecture, then dpkg -i each of the three.
This should be sufficient to get the services up and running–you can check with systemctl status rustdesk-hbbr and systemctl status rustdesk-hbbs. Once each service is running, the next step is finding your new Rustdesk server’s public key–which isn’t created until after the first time hbbs runs.
If you just installed everything normally from the .deb, you’ll find that key at /var/lib/rustdesk-server/id_ed25519.pub. Now, download and install the Rustdesk client onto another machine. Fire up the client, and get to configuring.
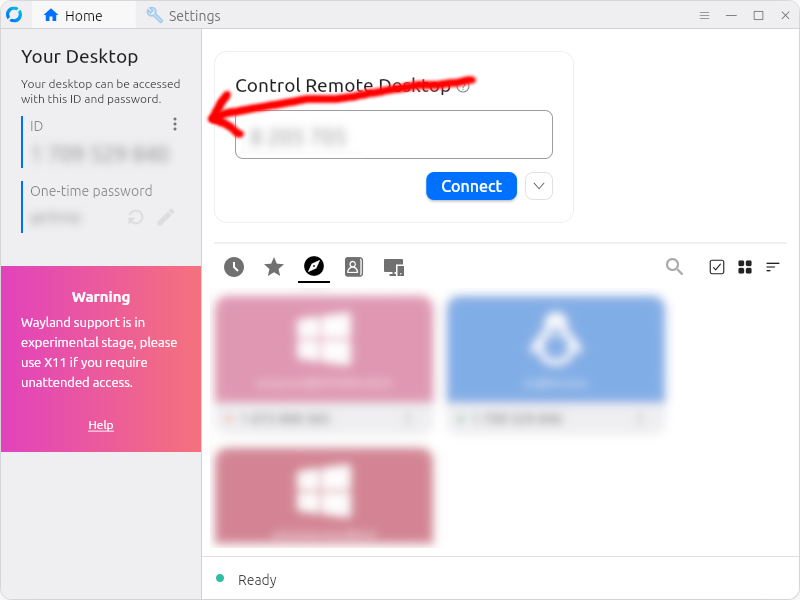
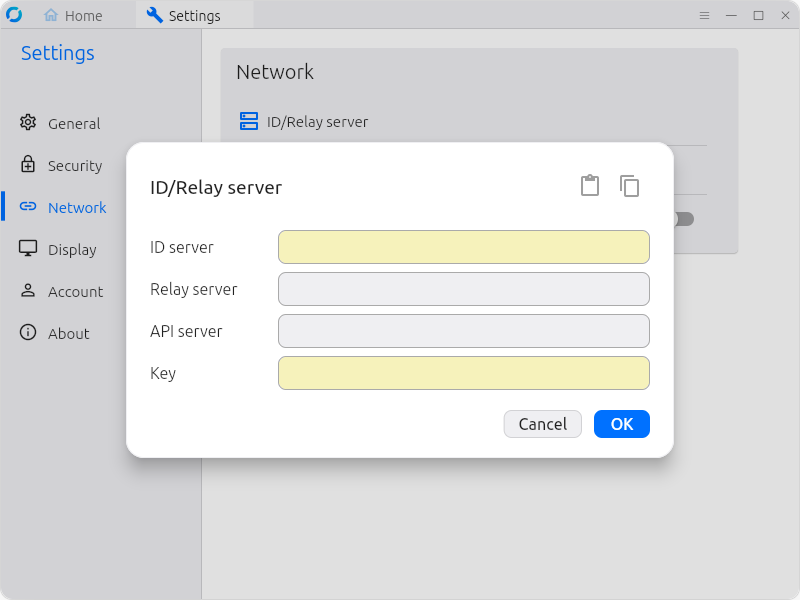
Once you’ve configured your first client to use your new relay server, you’ll want to click the copy icon on the upper right hand corner–this copies a string of apparent garbage to your clipboard; this garbage can later be imported into other Rustdesk clients.
To import your new configuration on other client systems later, just get that string of apparent garbage text into the system clipboard on the remote machine, then click the clipboard Paste icon just next to the Copy icon on the upper right. This will actually populate all fields of the ID/Relay server dialog on the new client just as they were configured on the old client. Tip: this probably isn’t particularly sensitive information, so you might consider saving it as a text file on an easy-to-access webserver somewhere.
At this point, you’re ready to rock. Once you’ve got the client software installed on any two machines and configured them to use your new relay server, you may connect to any of the machines thus configured, using the Rustdesk password you individually configure on each of those clients.
This is extremely early days for me–I literally just finished setting this up as a proof-of-concept earlier this morning–but so far, it looks pretty slick; I’m experiencing considerably lower latency with Rustdesk piped through a relay server in Atlanta, GA than I am with direct Spice connection to the same system via virt-manager and KVM!