Ubuntu has been getting less usable year by year ever since moving to systemd init. This year, the new papercut is that NetworkManager will violently conflict with–and override–anything you set in /etc/netplan, unless you manually tell it to bugger off.
This is a particular problem on systems that need network bridges (like KVM hosts), since NetworkManager will confidently blow away any consistent configuration you’ve done in /etc/netplan, in favor of the “duh, let’s DHCP every NIC we can find, this is probably just somebody’s laptop” defaults NetworkManager assumes you’ll want… despite having manually configured the interfaces already!
Configuration changes
Short version follows. Here’s your /etc/netplan/00-installer-config.yaml, assuming you’ve got two interfaces named enp67s0 and enp69s0, and would like to create a bridge named br0:
network: version: 2 renderer: networkd ethernets: enp67s0: dhcp4: false dhcp6: false enp69s0: dhcp4: false dhcp6: false bridges: br0: interfaces: [ enp67s0, enp69s0 ] dhcp4: true dhcp6: false # or if you want to static the interface, after setting dhcp4 to false: #addresses: [ x.x.x.x/yy ] #nameservers: # addresses: [ 8.8.8.8,1.1.1.1 ] #routes: # - to: default # via: x.x.x.x
So far, so good–but if you want a desktop interface available on this system, you’ll need to tell NetworkManager to leave your wired interfaces the hell alone. You do this by creating a new file, /etc/NetworkManager/conf.d/99-unmanaged-devices.conf:
In theory, once you’ve done this a simple sudo networkctl reload and sudo netplan apply will get you sorted–but I strongly recommend actually rebooting and verifying that your netplan configs are both applied and stay applied, since in my experience, running sudo netplan apply will work for the moment whether you’ve successfully nerfed NetworkManager or not.
Troubleshooting tips
If you still aren’t seeing the output you expect from ip a after the reboot, here are some troubleshooting tips:
bridge link show returns no output if your bridge is down, or something along the lines of 2: enp69s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master br0 state forwarding priority 32 cost 100 if the bridge is up and running.
networkctl status will show you lines like Foreign process ‘NetworkManager[3938]’ changed… if NetworkManager is screwing around with your configs.
If you need more a more verbose version of the above, try sudo journalctl -xeu systemd-networkd
If all else fails, just disable NetworkManager entirely. I wouldn’t recommend removing it–removing parts of the ubuntu-desktop metapackage can sometimes cause apt autoremove to try to nuke the entire desktop later–but a simple systemctl disable NetworkManager && systemctl stop NetworkManager will keep it from running and interfering with your wired configs–only potential issue there being losing the convenience of using the GUI to connect to Wi-Fi networks. But if you’re not using Wi-Fi on the system… this might be the easiest win.
Recommended additional steps
While you’re at it, go ahead and systemctl mask systemd-networkd-wait-online and systemctl mask NetworkManager-wait.online to disable the unlimited length timeouts for each of those services, which will otherwise add 120 entirely useless seconds to every single boot of your system.
If you’ve ever been as frustrated as I am at Ubuntu’s–technically, systemd’s–bog stubborn refusal to use the DNS servers you specify in your network configuration, this is the post for you.
I personally think it’s Bloody Stupid Johnson levels of dumb to insist on creating a local DNS resolver on every system instead of just using a nearby DNS resolver, but whatever. Ubuntu really REALLY fights you hard when you try to disable systemd-resolved, so here’s how to configure it properly instead.
This generally isn’t an issue on interfaces with purely static configurations–but on a netplan interface that uses DHCP at all, even with a staticallly configured DNS entry, systemd-resolved will ignore anything and everything but the DHCP-provided resolver when feeding its own resolver, which it will in turn force all of your applications to use.
Inside the new text file you’re creating, if you wanted to specify Google’s DNS you would use a stanza like so:
[Resolve] DNS=8.8.8.8
Once you’ve created the new file with the appropriate configuration stanza, you’ll need to restart the local resolver:
sudo systemctl restart systemd-resolved
And now, FINALLY, even though your applications are forced to query the local resolver that ignores your network configs… you can at least configure that network resolver with its OWN configs that will then work.
Of course, that means that any DNS setting in /etc/netplan is a completely ignored waste of characters. Welcome to systemd.
As usual, I’m self-documenting a project while I work on it. Rustdesk is an open source remote control utility that caught my eye about a year ago; it’s cross platform and allows you to self-host your own “relay server” so that you can connect securely from one machine on a private network to a machine on a different private network without needing to faff about with port forwarding or similar nonsense.
Most of the docs seem focused around running it as a Docker instance, which I didn’t particularly want to do. They also weren’t clear AT ALL about where important files live, how they’re run, etc.
First up: you’ll need to install THREE separate .deb files. Go to the rustdesk-server releases page here and download the rustdesk-server-hbbr, rustdesk-server-hbbs, and rustdeskserver-utils packages for your architecture, then dpkg -i each of the three.
This should be sufficient to get the services up and running–you can check with systemctl status rustdesk-hbbr and systemctl status rustdesk-hbbs. Once each service is running, the next step is finding your new Rustdesk server’s public key–which isn’t created until after the first time hbbs runs.
If you just installed everything normally from the .deb, you’ll find that key at /var/lib/rustdesk-server/id_ed25519.pub. Now, download and install the Rustdesk client onto another machine. Fire up the client, and get to configuring.
First, click the three-dot menu next to your ID, in the upper left corner of the client.
Next, from the general Rustdesk client Settings page, click Network.
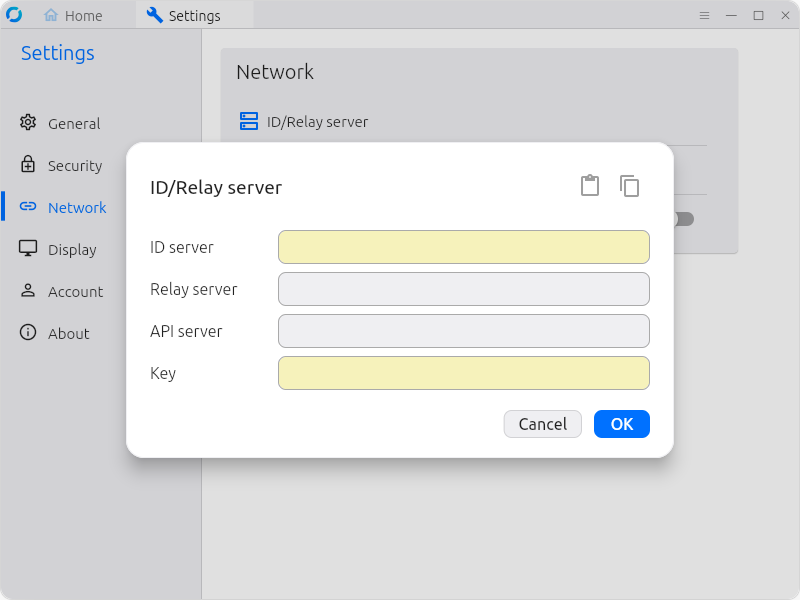
You should only need to fill in the highlighted two fields here: ID server and Key. Unless you’ve got a very non-standard config, Rustdesk figures Relay and API servers out for itself.
Once you’ve configured your first client to use your new relay server, you’ll want to click the copy icon on the upper right hand corner–this copies a string of apparent garbage to your clipboard; this garbage can later be imported into other Rustdesk clients.
To import your new configuration on other client systems later, just get that string of apparent garbage text into the system clipboard on the remote machine, then click the clipboard Paste icon just next to the Copy icon on the upper right. This will actually populate all fields of the ID/Relay server dialog on the new client just as they were configured on the old client. Tip: this probably isn’t particularly sensitive information, so you might consider saving it as a text file on an easy-to-access webserver somewhere.
At this point, you’re ready to rock. Once you’ve got the client software installed on any two machines and configured them to use your new relay server, you may connect to any of the machines thus configured, using the Rustdesk password you individually configure on each of those clients.
This is extremely early days for me–I literally just finished setting this up as a proof-of-concept earlier this morning–but so far, it looks pretty slick; I’m experiencing considerably lower latency with Rustdesk piped through a relay server in Atlanta, GA than I am with direct Spice connection to the same system via virt-manager and KVM!
If you’re running Windows VMs beneath a Linux KVM host, you’ve very likely been plagued by an annoying issue: they start up with the wrong time by several hours, every time they’re rebooted, no matter what you do.
The issue is that Windows syncs its time with the local hardware clock, and in KVM’s case, it generally provides VMs with a “hardware” clock set to UTC regardless of what the real hardware clock’s time zone is set to.
Here’s the fix: on your Windows VM, create a new text file called UTCtime.reg, and populate it with the following:
Now you can just double-click the patch file to import it into the VM’s registry, then reboot the VM. When it comes back up, it’ll come back up with the correct time (assuming your hardware clock is set to the correct time, of course).
IDK about y’all, but this one had been pissing me off for years; it’s nice to finally have a fix for it!
Recently, I acquired a new client with a massive load of technical debt (in other words: a new client). The facility internet connection appeared to go down for an hour or two every day, typically in the mid-afternoon.
Complicating things tremendously, this new client had no insight into its own infrastructure: the former IT person had left them with no credentials or documentation for anything. So I was limited to completely unprivileged tools while troubleshooting.
The first major thing I discovered was a somewhat deranged Adtran Netvanta router, as installed by the ISP. When I got a Linux laptop onto the network and issued a dhclient -v, I could see both that the Netvanta was acting as DHCP server, and that it was struggling badly.
My laptop DHCPDISCOVERed about twelve times before getting a DHCPOFFER from the Netvanta, to which it eagerly replied with a DHCPREQ for the offered address… which the Netvanta failed to respond to. My laptop DHCPREQ’d twice more, before giving up and moving back to DHCPDISCOVER. Eventually, the Netvanta DHCPOFFERed again, my laptop DHCPREQ’d, and this time on the third try, the punch-drunk Netvanta DHCPACK’d it, and it was on the network… after a solid two minutes of trying to get an IP address.
Alright, now I knew both that DHCP was coming from the ISP router, and that it was deranged. Why? And could I do anything about it?
The Netvanta was bolted into a wall-mounted half-cab directly touching its sibling Adva, so tightly together you couldn’t slide a playing card between the two. Both devices had functional active cooling, so this wasn’t necessarily a problem… but when I ran a bare finger along the rear face of the chassis, it was a lot warmer than I liked. So, I unbolted one side of it, and re-bolted it caddycorner with one side higher than the other, which gave some external airflow across the chassis.
Although now it looks like I’m an idiot who can’t line up boltholes, the triangles of airspace on the bottom left and top right of the Netvanta give it some convection space to shed heat from its metal chassis.
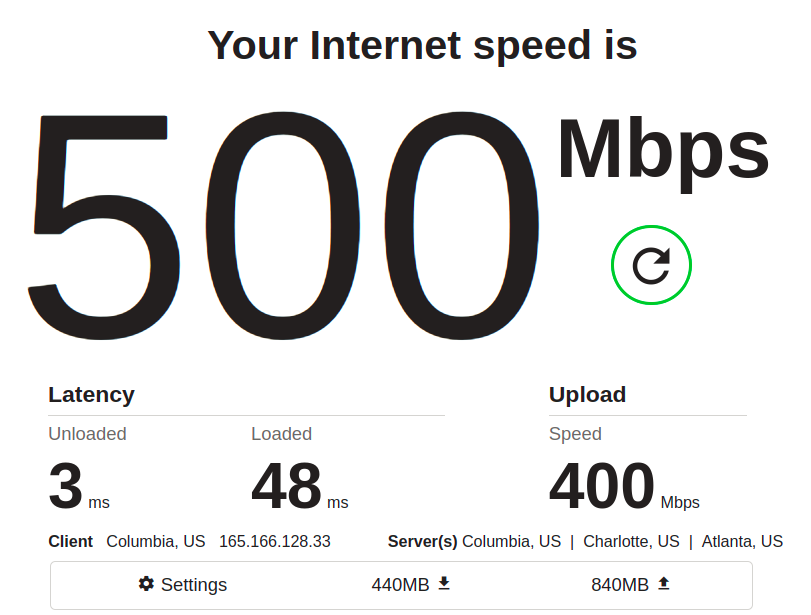
And to my great delight, when I got back to my commandeered office (the former IT guy’s personal dungeon), dhclient -v now completed in under 10ms, every time: DHCPDISCOVER–>DHCPOFFER–>DHCPREQ–>DHCPACK with no stumbles at all. As an added bonus, my exploratory internet speedtests went from 65Mbps to 400Mbps!
This made an enormous improvement in the facility’s network health, but there were still problems: the next day, my direct report got frustrated enough with the facility network to turn on a cell phone hotspot. Luckily, I’d already spotted another problem in the same rack:
Whoever installed all this gear apparently didn’t realize there’s a minimum bend radius for fiberoptics: and for multi-mode fiber like you see above, that minimum bend radius is 30x the diameter of the jacketed pair. I didn’t try to break out a ruler, but that looked a lot more like 10x the jacket diameter than 30x to me, so off I went to grab a five-pack of LC to LC multi-mode patch cables.
Keeping to our theme of me looking like a drunken redneck while actually improving things technically, I used some mounting points on the face of an abandoned Cisco switch mounted several units higher in the cabinet as a centerpoint anchor for my new patch cables. Does it look stupid? Yes. Does it keep things out of the way without fracturing the glass on the inside of my optic cables? Also yes.
The performance difference here was harder to spot–especially since I needed to perform it on a weekend with the facility empty except for myself–but if you know what you’re looking for, it’s there. Prior to replacing the patch cables, an iperf3 run to one of my internet-based servers had a TCP congestion window of 3.00MiB:
After replacing the too-tightly-bent fiber patch cables, the raw speed didn’t increase much–but the TCP congestion window doubled to 6.00MiB. This is an excellent sign which–if you understand TCP congestion windowing algorithms–strongly implies a significant decrease in experienced latency.
This apparent improvement in latency is confirmed with simpler web-based speedtests to fast.com, which showed an unloaded latency of 3ms and a loaded latency of 48-85ms prior to replacing the cables. After replacing them, fast.com consistently showed unloaded latency of 2ms… and loaded latency of <10ms.
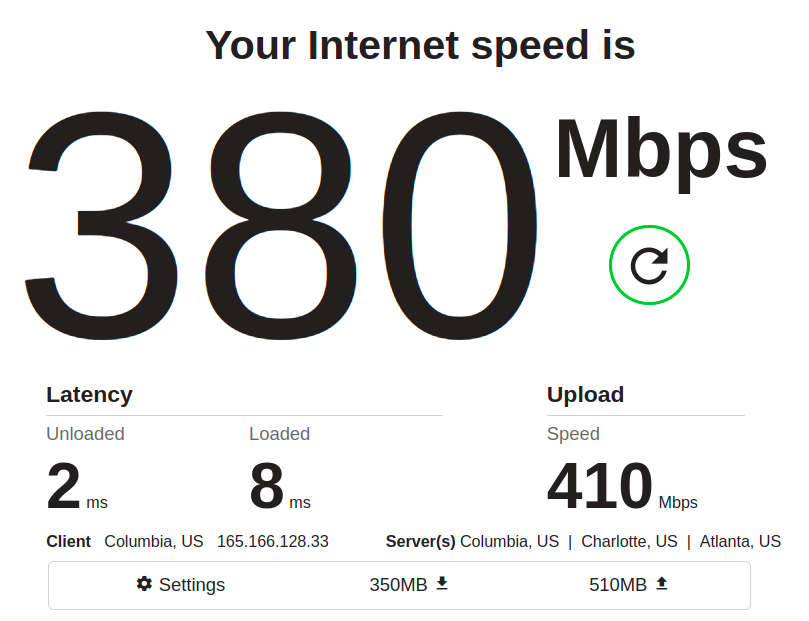
Again, pay attention to the latency. In the “before” shot above, we see a maxed-out download throughput of 500Mbps, which is nice… and in fact, at first glance, you might mistakenly think this is a better result than the “after” we see below:
Oh no, you might think–download speed decreased from 500Mbps to 380Mbps! What did we do wrong? That’s the tricky part; we didn’t do anything wrong–something else on the network just siphoned off some of the available throughput while the test was running.
The important things to notice are, as mentioned, latency: it’s easy to dismiss the unloaded latency (meaning, how quickly pings return when the main bulk of the test isn’t running) decreasing from 3ms to 2ms. It’s only 1ms, after all… but it’s also a 33% improvement, and it held precisely consistent across many runs.
More conclusively, the loaded latency (time to return a ping when there’s lots of data moving) decreased by several hundred percent, and that result was also consistent across several runs.
There are almost certainly more gremlins to find and eliminate in this long-untended network, but we’re already in a much better position than we started from.
I recently bought a server which came with Samsung PM1643 SSDs. Trying to install Ubuntu on them didn’t work at first try, because the drives had 520 byte sectors instead of 512 byte.
Luckily, there’s a fix–get the drive(s) to a WORKING Ubuntu system, plug them in, and use the sg_format utility to convert the sector size!
Yep, it’s really that easy. Be warned, this is a destructive, touch-every-sector operation–so it will take a while, and your drives might get a bit warm. The 3.84TB drives I needed to convert took around 10 minutes apiece.
On the plus side, this also fixes any drive slowdowns due to a lack of TRIM, since it’s a destructive sector-level format.
I’ve heard stories of drives that refused to sg_format initially; if you encounter stubborn drives, you might be able to unlock them by dding a gigabyte or so to them–or you might need to first sg_format them with --size=520, then immediately and I mean immediately again with --size=512.
There unfortunately are still a few stumbling blocks toward getting a properly, fully-working virt-manager setup running under WSL2 on Windows 11.
apt install virt-manager just works, of course–but getting WSL2 to properly handle hostnames and SSH key passphrases takes a bit of tweaking.
First up, install a couple of additional packages:
apt install keychain ssh-askpass
The keychain package allows WSL2 to cache the passphrases for your SSH keys, and ssh-askpass allows virt-manager to bump requests up to you when necessary.
If you haven’t already done so, first generate yourself an SSH key and give it a passphrase:
me@my-win11:~# ssh-keygen Generating public/private rsa key pair. Enter file in which to save the key (~/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in ~/.ssh/id_rsa Your public key has been saved in ~/.ssh/id_rsa.pub
You will also need to configure keychain itself, by adding the following to the end of your .bashrc:
# For Loading the SSH key /usr/bin/keychain -q --nogui $HOME/.ssh/id_rsa source $HOME/.keychain/$HOSTNAME-sh
Now, you’ll enter in your SSH key passphrase each time you open a WSL2 terminal, and it will remember it for SSH sessions opened via that terminal (or via apps opened from that terminal, eg if you type in virt-manager).
If you like to set hostnames in /etc/hosts to make your virt-manager connections look more reasonable, there’s one more step necessary. By default, for some reason WSL2 clobbers /etc/hosts each time it’s started.
You can defang this by creating /etc/wsl.conf and inserting this stanza:
[network] generateHosts = false
Presto, you can now have a nice, secure, and well-working virt-manager under your Windows 11 WSL2 instance!
I also edited this screenshot with Ubuntu GiMP installed under WSL2 with apt install gimp. Because of course I did.
One final caveat: I do not recommend trying to create a shortcut in Windows to open virt-manager directly.
You can do that… but if you do, you’re liable to break things badly enough to require a Windows reboot. Windows 11 really doesn’t like launching WSL2 apps directly from a batch file, rather than from within a fully-launched WSL2 terminal!
With that important disclaimer out of the way… when you’re stuck in the world’s worst apt -f install loop and can’t figure out any other way to get the damn thing unwedged when there’s a half-installed package (eg if you’ve removed an /etc directory for a package you installed before, and this breaks an installer script—or the installer script “knows you already have it” and refuses to replace a removed config directory), this is the nuclear option:
sudo nano /var/lib/dpkg/status
Remove the offending package (and any packages that depend on it) entirely from this file, then apt install the offending package again.
If you’re still broken after that… did I mention all warranties null and void? This is an extremely nuclear option, and I really wouldn’t recommend it outside a throwaway test environment; you’re probably better off just nuking the whole server and reinstalling.
With that said, the next thing I had to do to clean out the remnants of the mysql/mariadb coinstall debacle that inspired this post was:
This got me out of a half-broken state on a machine that somebody had installed both mariadb-server and mysql-server on, leaving neither working properly.
One of the questions that comes up time and time again about ZFS is “how can I migrate my data to a pool on a few of my disks, then add the rest of the disks afterward?”
If you just want to get the data moved and don’t care about balance, you can just copy the data over, then add the new disks and be done with it. But, it won’t be distributed evenly over the vdevs in your pool.
Don’t fret, though, it’s actually pretty easy to rebalance mirrors. In the following example, we’ll assume you’ve got four disks in a RAID array on an old machine, and two disks available to copy the data to in the short term.
Step one: create the new pool, copy data to it
First up, we create a simple temporary zpool with the two available disks.
Simple. Now you’ve got a ZFS mirror named temp, and you can start copying your data to it.
Step two: scrub the pool
Do not skip this step!
zpool scrub temp
Once this is done, do a zpool status temp to make sure you don’t have any errors. Assuming you don’t, you’re ready to proceed.
Step three: break the mirror, create a new pool
zpool detach temp /dev/disk/by-id/disk1
Now, your temp pool is down to one single disk vdev, and you’ve freed up one of its original disks. You’ve also got a known good copy of all your data on disk0, and you’ve verified it’s all good by using a zpool scrub command in step two. So, destroy the old machine’s storage, freeing up its four disks for use.
zpool create tank /dev/disk/by-id/disk1 mirror /dev/disk/by-id/disk2 /dev/disk/by-id/disk3 mirror /dev/disk/by-id/disk4 /dev/disk/by-id/disk5
Now you’ve got your original temporary pool named temp, and a new permanent pool named tank. Pool “temp” is down to one single-disk vdev, and pool “tank” has one single-disk vdev, and two mirror vdevs.
Step four: copy your data from temp to tank
Copy all your data one more time, from the single-disk pool “temp” to the new pool “tank.” You can use zfs replication for this, or just plain old cp or rsync. Your choice.
Step five: scrub tank, destroy temp
Do not skip this step.
zpool scrub tank
Once this is done, do a zpool status tank to make sure you don’t have any errors. Assuming you don’t, now it’s time to destroy your temporary pool to free up its disk.
zpool destroy temp
Almost done!
Step six: attach the final disk from temp to the single-disk vdev in tank
zpool attach tank /dev/disk/by-id/disk0 /dev/disk/by-id/disk1
That’s it—you now have all of your data imported to a six-disk pool of mirrors, and all of the data is evenly distributed (according to disk size, at least) across all vdevs, not all clumped up on the first one to be added.
You can obviously adjust this formula for larger (or smaller!) pools, and it doesn’t necessarily require importing from an older machine—you can use this basic technique to redistribute data across an existing pool of mirrors, too, if you add a new mirror vdev.
The important concept here is the idea of breaking mirror vdevs using zpool detach, and creating mirror vdevs from single-disk vdevs using zpool attach.
You want to reclaim space on a ZFS pool by deleting some old snapshots. Problem is, you take snapshots frequently, so they all have deceptively low REFER values—REFER only shows you the space unique to a snapshot, so it’s entirely possible that deleting two snapshots that each show REFER of 1MiB will actually remove 100GiB of data.
How, you ask? Well, if that 100GiB of data is common to both snapshots, it won’t show up on the REFER of either—but if it was present in only those two snapshots, deleting them both unlinks that 100GiB and marks it free again.
Luckily, zfs destroy has a dry-run option, and can be used to delete sequences of snapshots. So you can see before-hand how much space will be reclaimed by deleting a sequence of snapshots, like this:
root@box:~# zfs destroy -nv pool/dataset@snap4%snap8 would destroy pool/dataset@snap4 would destroy pool/dataset@snap5 would destroy pool/dataset@snap6 would destroy pool/dataset@snap7 would destroy pool/dataset@snap8 would reclaim 25.2G