I am INDECENTLY excited about some plans for further btrfs development that I just got confirmed on the mailing list.
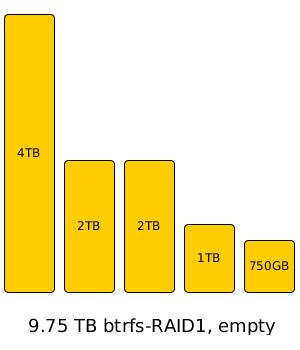
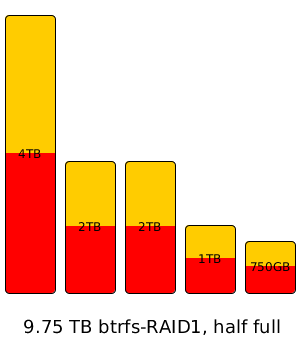
Btrfs can already support a redundant array on an arbitrary collection of “mutt” hard drives via btrfs-raid1 – as an example, say you’ve got five hard drives lying around; a 4TB drive, two 2TB drives, a 1TB drive, and an old 750GB drive. You can dump all of those mutts into one btrfs-raid1 array for a total of 9.75TB of raw capacity, and roughly half that (4.5TB-ish) of usable capacity. The btrfs-raid1 will just store two copies of each data block it writes on two separate drives, doing its best to keep each drive in the array about the same percentage of its overall capacity “full”.
This is actually a huge win for midmarket and enterprise as well as for small business and prosumers – if you assume a more business-y environment with matched drives, the performance characteristics of an array like this are very interesting; you aren’t tied to stripes, you don’t have to do a read-write-rewrite dance when data is modified, and you don’t have to have an extremely performance-penalized restriping event if a drive fails and is replaced – the array can just quickly write new redundant copies of any orphaned blocks out to the new replacement drives, without needing to disturb (or, worse, read / write / rewrite) blocks that weren’t orphaned.
For small business and especially prosumer, of course, the benefits are even more obvious – the world is littered with people who want to throw an arbitrary number of arbitrarily sized “mutt” drives they have lying around into one big array, and finally, they can do so – quickly, easily, effectively. The only drawback is that you’re locked into n/2 storage efficiency – since this is still a system that relies on a redundant copy of each data block to be written to a different disk than the first copy is written to, the 9.75TB array up there will only be able to store about 4.5TB of data, which is just not efficient enough for a lot of people, especially the small business and prosumer types.
OK, now we’ve wrapped our brain around the idea of a “raid1” that just distributes data blocks evenly around an arbitrary array while making sure that redundant blocks are on separate physical disks – and can handle weird numbers and sizes of disks with aplomb. (I’ve personally tested a btrfs-RAID1 with three equal sized drives, and yes, it can store half the raw capacity of all three drives just fine.) What’s next?
For those folks who aren’t satisfied with n/2 storage efficiency… there are plans on the roadmap for striped/parity storage that ALSO isn’t tied to the number of physical drives present. Let’s say you have five disks and you’re satisfied with single-disk fault tolerance – you might choose to create a striped array with four data blocks and one parity block per stripe. This is pretty obvious and easy to picture (if it were actually tied directly to disks, and the disks had to be identically sized, we’d have just described a RAID3 array). Now, what happens if you add two more disks to your array without changing your stripe size and parity level? No problem – (future versions of) btrfs will just distribute blocks from each stripe equally around the array of physical disks, so that “half full” on the array roughly corresponds to “half full” on each individual disk as well, just like we demo’ed above on the btrfs-raid1 array.
I am VERY excited about being able to decide, for example, “I want 80% storage efficiency and single-failure fault tolerance”, and therefore being able to select a stripe length of 4 data blocks and one parity block… or “I want 75% storage efficiency and two-failure fault tolerance” and selecting a stripe length of 6 data blocks and 2 parity blocks… and in either case, to then be able to say “OK, now I want to expand my array with these six new drives I just bought” and be able to do so just as simply as adding the new drives, without worrying about how that will affect my storage efficency, fault tolerance level, or having to do a severely expensive and somewhat dangerous “restriping” of the array.
We are living in very interesting times, when it comes to data storage, and I have a feeling the majority of the storage industry – even the relatively well-informed bits that keep up with ZFS, Ceph, OrangeFS, etc – are going to be utterly gobsmacked and scrambling for footing when btrfs hits mainstream.