Recently on r/zfs, the topic of ZIL (ZFS Intent Log) and SLOG (Secondary LOG device) came up again. It’s a frequently misunderstood part of the ZFS workflow, and I had to go back and correct some of my own misconceptions about it during the thread. ixSystems has a reasonably good explainer up – with the great advantage that it was apparently error-checked by Matt Ahrens, founding ZFS developer – but it could use a diagram or two to make the workflow clear.
In the normal course of operations on a basic pool with no special devices (such as a SLOG), the write workflow looks like this:
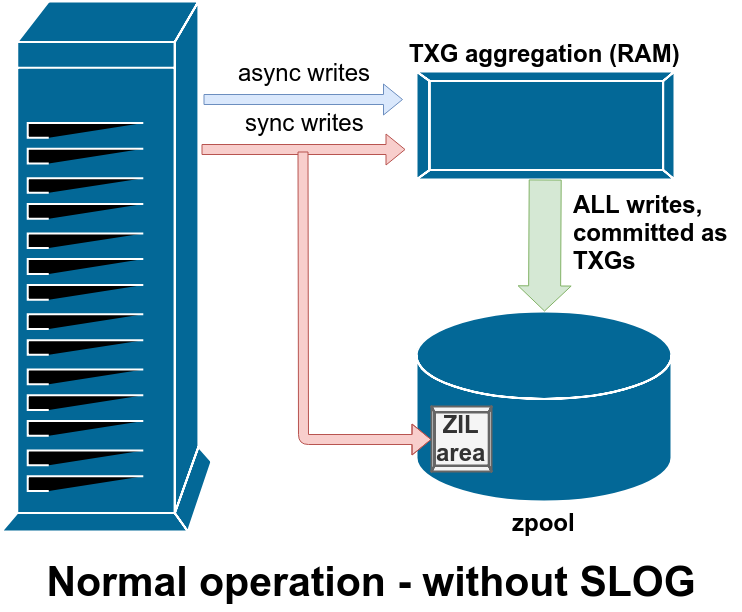
Unless explicitly declared as synchronous (by opening with O_SYNC set, or manually calling sync()), all writes are asynchronous. And – here’s the bit I find most people misunderstand – all writes, including synchronous writes, are aggregated in RAM and committed to the pool in TXGs (Transaction Groups) on a regular basis.
The difference with sync writes is, they’re also written to a special area of the pool called the ZIL – ZFS Intent Log – in parallel with writing them to the aggregator in RAM. This doesn’t mean the sync writes are actually committed to main storage immediately; it just means they’re buffered on-disk in a way that will survive a crash if necessary. The other key difference is that any asynchronous write operation returns immediately; but sync() calls don’t return until they’ve been committed to disk in the ZIL.
I want you to go back and look at that diagram again, though, and notice that there’s no arrow coming out of the ZIL. That’s not a bug – in normal operation, blocks written to the ZIL are never read from again; the sync writes still get committed to the main pool in TXGs from RAM alongside the async writes. The sync write blocks in the ZIL get unlinked after the copies of them in RAM get written out to the pool in TXGs.
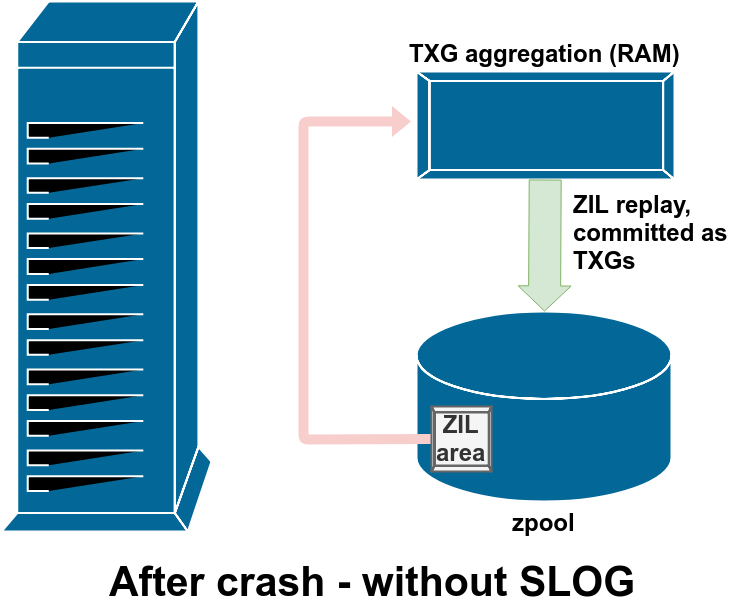
During the import process for a zpool, ZFS checks the ZIL for any dirty writes. If it finds some (due to a kernel crash or system power event), it will replay them from the ZIL, aggregating them into TXG(s), and committing the TXG(s) to the pool as normal. Once the dirty writes from the ZIL have been committed and the ZIL itself cleared, the pool import can proceed normally and we’re back to diagram 1, normal operation.
Why would we want a SLOG?
While normal operation with the ZIL works very reliably, it introduces a couple of pretty serious performance drawbacks. With any filesystem, writing small groups of blocks to disk immediately without benefit of aggregation and ordering introduces serious IOPS (I/O Operations per Second) penalties.
With most filesystems, sync writes also introduce severe fragmentation penalties for any future reads of that data. ZFS avoids the increased future fragmentation penalty by writing the sync blocks out to disk as though they’d been asynchronous to begin with. While this avoids the future read fragmentation, it introduces a write amplification penalty at the time of committing the writes; small writes must be written out twice (once to ZIL and then again later in TXGs to main storage).
Larger writes avoid some of this write amplification by committing the blocks directly to main storage, committing a pointer to those blocks to the ZIL, and then only needing to update the pointer when writing out the permanent TXG later. This is pretty effective at minimizing the write throughput amplification, but doesn’t do much to mitigate write IOPS amplification – and, please repeat with me, most storage workloads bind on IOPS.
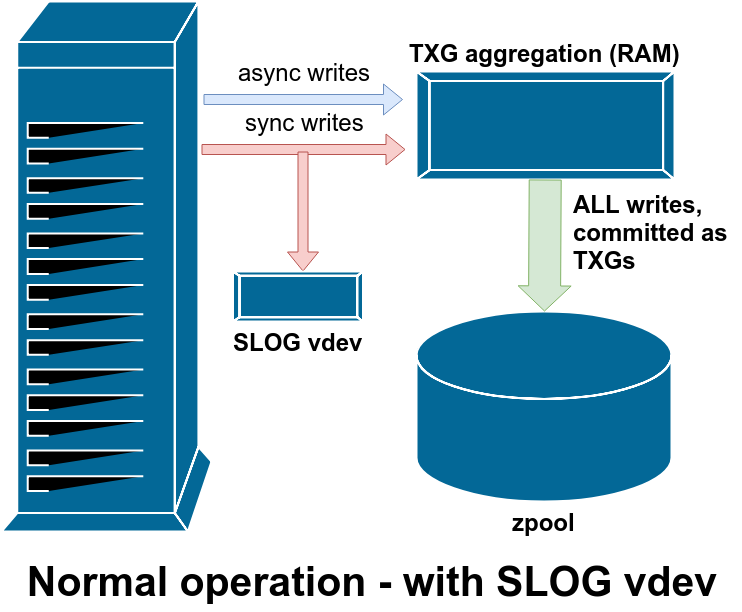
So if your system experiences a lot of sync write operations, a SLOG – Secondary LOG device – can help. The SLOG is a special standalone vdev that takes the place of the ZIL. It performs exactly like the ZIL, it just happens to be on a separate, isolated device – which means that “double writes” due to sync don’t consume the IOPS or throughput of the main storage itself. This also means the latency of the sync write operations themselves improves, since the call to sync() doesn’t return until after the data has been committed temporarily to disk – in this case, to the SLOG, which should be nice and idle in comparison with our busy main storage vdevs.
Ideally, your SLOG device should also be extremely fast, with tons of IOPS – read “fast solid state drive” – to get that sync write latency down as low as possible. However, the only speed we care about here is write speed; the SLOG, just like the ZIL, is never read from at all during normal operation. It also doesn’t need to be very large – just enough to hold a few seconds’ worth of writes. Remember, every time ZFS commits TXGs to the pool, it unlinks whatever’s in the SLOG/ZIL!
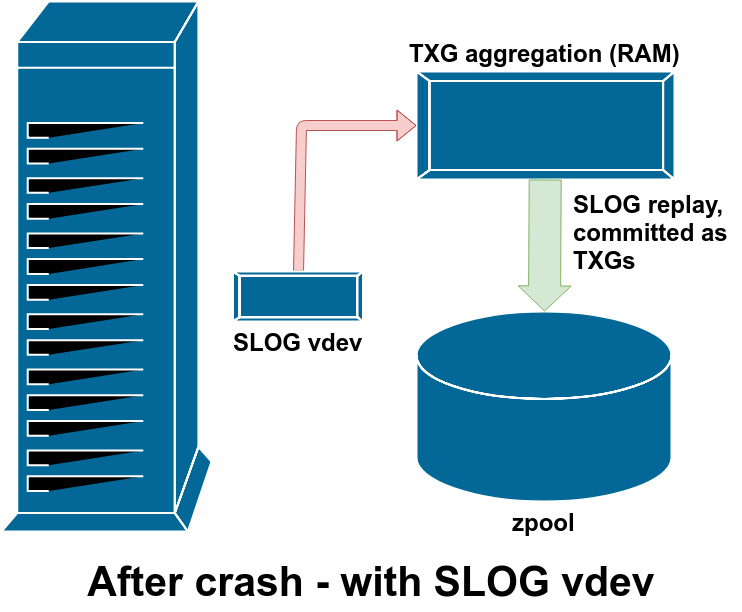
Pictured above is the only time the SLOG gets read from – after a crash, just like the ZIL. There really is zero difference between SLOG and ZIL, apart from the SLOG being separate from the main pool vdevs in order to conserve write throughput and IOPS, and minimize sync write latency.
Should I set sync=always with a fast SLOG?
Yes, you can zfs set sync=always to force all writes to a given dataset or zvol to be committed to the SLOG. But it won’t make your asynchronous writes go any faster. Remember, asynchronous write calls already return immediately – you literally can’t improve on that, no matter what you do.
You also can’t materially improve throughput, since the SLOG is only going to buffer a few seconds of writes before main commits to the pool via TXGs from RAM kick in.
The potential benefit to setting zfs sync=always isn’t speed, it’s safety.
If you’ve got applications that notoriously write unsafely and tend to screw themselves after a power outage or other crash – eg any databases using myISAM or other non-journalling storage engine – you might decide to set zfs sync=always on the dataset or zvol containing their back ends, to make certain that you don’t end up with a corrupt db after a crash. Again, you’re not going faster, you’re going safer.
OK, what about sync=disabled?
No matter how fast a SLOG you add, setting sync=always won’t make anything go faster. Setting sync=disabled, on the other hand, will definitely speed up any workload with a lot of synchronous writes.
sync=disabled decreases latency at the expense of safety.
If you have an application that calls sync() (or opens O_SYNC) far too often for your tastes and you think it’s just a nervous nelly, setting sync=disabled forces its synchronous writes to be handled as asynchronous, eliminating any double write penalty (with only ZIL) or added latency waiting for on-disk commits. But you’d better know exactly what you’re doing – and be willing to cheerfully say “welp, that one’s on me” if you have a kernel crash or power failure, and your application comes back with corrupt data due to missing writes that it had depended on being already committed to disk.
Thanks for this post. Before it’s reading i didn’t understand ZIL and SLOG very well. Manuals aren’t so precise about this. Thanks again. Joseph.
Thank you very much for this and the benchmark article. They are clear, illustrated and well written.
However, I see a massive difference in performance between sync=standard and sync=always.
Would you know the difference between the sync=standard vs sync=always or between sync=standard vs sync=disable?
Thank you.
Thanks, this was an extremely helpful read. I realized I had no idea how the ZIL actually worked from this.
Explained very easily, thank you very much for this post.
sync=always forces every write, whether it would normally be sync or not, to go through the ZIL. That’s going to impose a throughput bottleneck even on systems with very fast LOG vdevs, and an absolutely enormous bottleneck on systems with no SLOG, or with a not-very-fast SLOG.
sync=standard writes sync writes sync, and lets async writes be async.